
涅槃博客
记录生活,分享世界
现在时间
每日壁纸

南极洲冰山上的阿德利企鹅 (© Patrick J. Endres/Getty Images)










最新评论


汲墨 Lv.1
3月21日
老师您好,我将Memos添加到独立页面后,点击分类时无法跳转到对应的memos内容分类,实际页面跳转到了 https://www.lniaen.com/index.php/undefined/api/v1/memo?creatorId=1&tag=% E6%97% A5% E5% B8% B8&rowStatus=NORMAL&limit=50,而不是memos.lniaen.com。
请问这是我配置有问题吗?

可爱 Lv.1
2023年12月27日
而且我发现我查到的文件路径好像跟你这个也不太一样,我没有 xxxxxxxxxxxxxxxxxx/merged的 只有xxxxxxxxxxxxxxxxxx/diff
可爱 Lv.1
2023年12月27日
您好,博主,因为上个版本的图标什么的都加载不出来,我升级后重新按照教程修改了一遍,但是好像并未生效!也重启过!改完docker restart fa602e015387 根据PID重启的 重启完后监控页面的 流量那些都没出来,我试过无痕模式也是没有,想请教下博主会是什么原因呢?


Loading......
----涅槃


love2wind
November 1, 2023,📝教程
热文为博客添加Memos滚动轮播及Memos聚合页

用上Memos已经很长时间了,经过这段时间的使用,感觉还是非常不错的,不了解 Memos 的可以去官方仓库看看,至于Memos的搭建和使用后面抽时间再写教程(主要欠的坑太多了),或者看看其他博主...
love2wind
April 17, 2023,📝教程
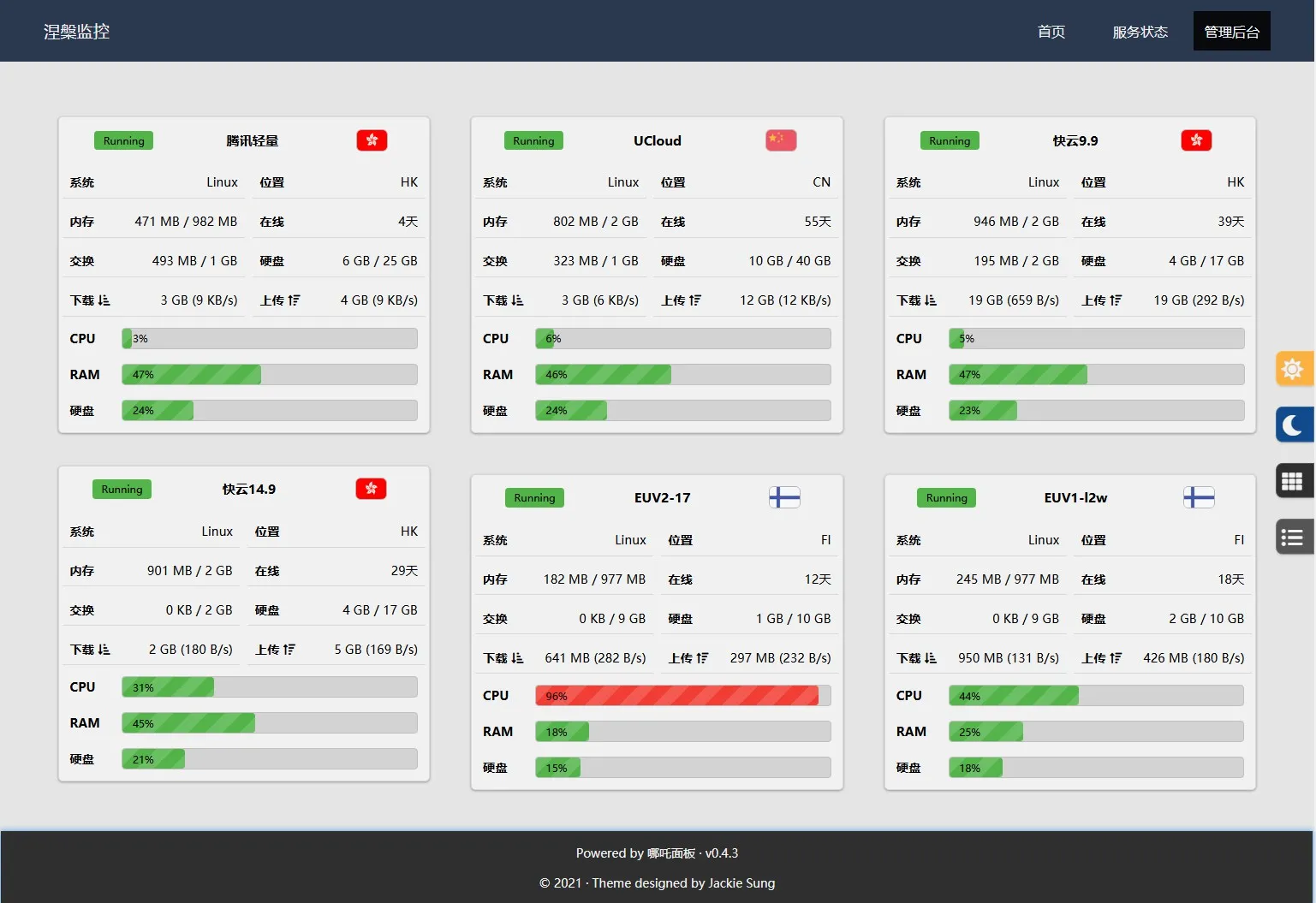
头条超级漂亮哪吒面板最新版透明主题
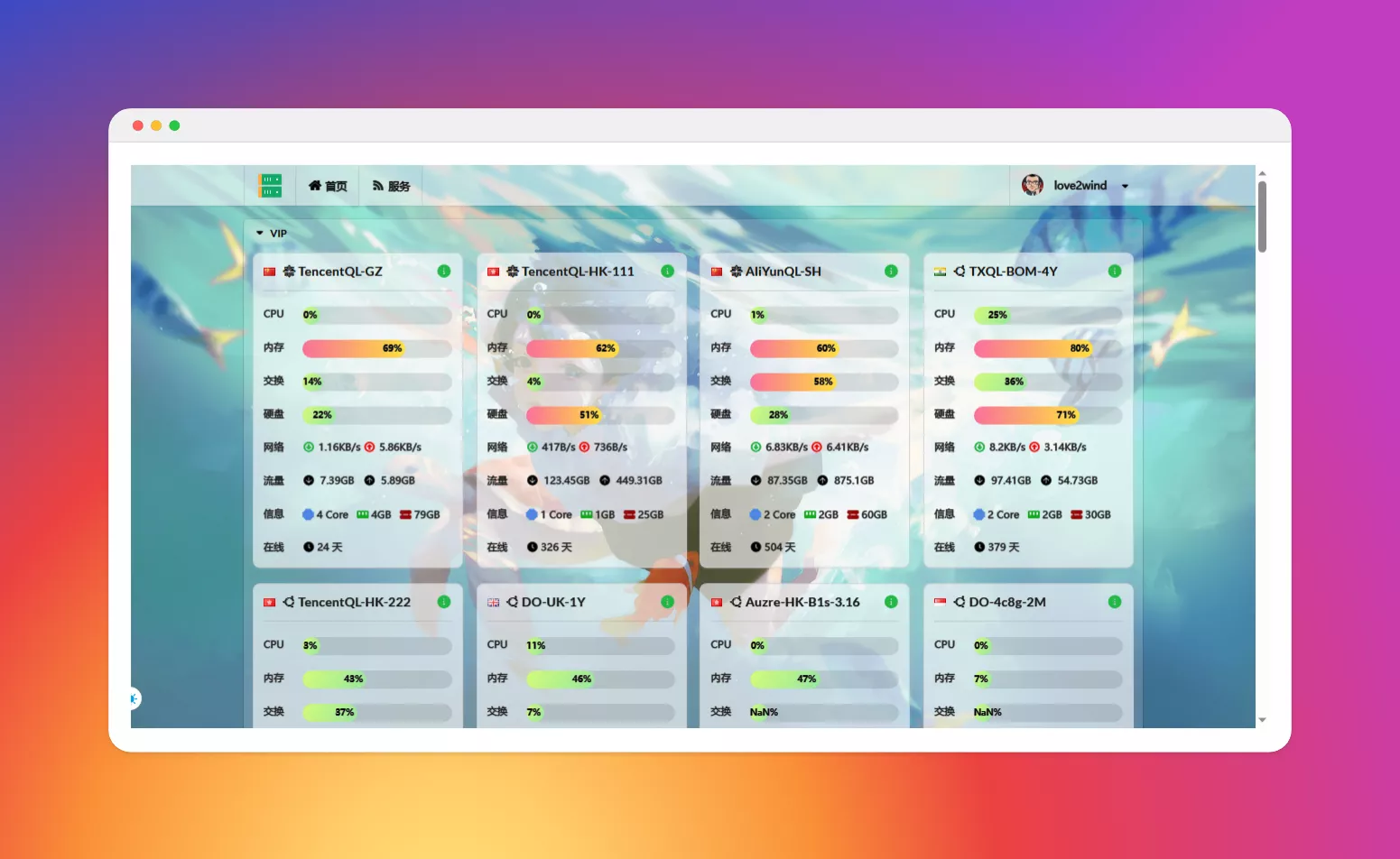
[cards css="info" type="图标无法加载问题的解决方法"]由于StaticFile国内CDN缓存策略的变更,低于v0.15.20的面板前端可能会出现图标无法加载的问题(COR...
love2wind
April 11, 2023,📝教程
头条TeraCLOUD更名为InfiniCLOUD,注册就送45G+15G的WebDAV网盘

为什么推荐TeraCLOUD(InfiniCLOUD)TeraCloud是一家老牌的日本网盘,因为支持WebDAV同步而且国内访问速度相当可观,所以很受国内用户欢迎,涅哥在21年就开始使用了。国...
love2wind
March 9, 2023,🐙Github
头条Chevereto V4.0.7 开心版!
经过这阵子Chevereto的开发逐步稳定,且距离上次 CheveretoChina 发布已过了一年,Chevereto 的里程碑 V4.0 aka Macanudo。CheveretoChin...
love2wind
November 7, 2022,🧡日志
头条免费图床大测评【2023.12.19更新】

[cards css="info" type="关于外链图床"]图片外链(图床)可以用于论坛、网站、评论、聊天等;下面推荐一些免费稳定好用的图片外链图床。如果你知道更多免费图床网站,可以通过下方...
About
已经忘了什么时候开始用错爱涅槃做网名了,但从一开始就用 love2wind 作为ID,毕竟已经过了很长很长的时间了。本人爱好很多,多到好像什么都会点,又什么都不会(囧)!从很早开始就折腾网站,从论坛到博客,DIscz、wordpress、还有很多换七八糟的,但都没能坚持下来,博客算是时间长的,断断续续也有快十几年了,就这样吧,也不知道要介绍些什么?随便敲点字的样子(捂脸)。
I have forgotten when I started using the wrong love Nirvana as my screen name, but I used love2wind as the ID from the beginning. After all, a long, long time has passed. I have a lot of hobbies, so many that seem to be good at everything, but nothing at all (囧)! I’ve been tossing about websites from very early on, from forums to blogs, DIscz, wordpress, and many other things, but they haven’t been able to stick to it. The blog is long, and it’s been on and off for more than ten years, so be it. , Don’t know what to introduce? Just type some words (cover your face),
关注我们
 官方QQ群 |  我的微信号 |  微信公众号 |  |
最新教程
- 热文 类flemo应用:Memos的搭建部署及美化修改 2601 阅读
- 热文 为博客添加Memos滚动轮播及Memos聚合页 2577 阅读
- 头条 超级漂亮哪吒面板最新版透明主题 7966 阅读
- 头条 TeraCLOUD更名为InfiniCLOUD,注册就送45G+15G的WebDAV网盘 7172 阅读
- 头条 哪吒面板透明自定义主题 7107 阅读
- 头条 nom.za免费域名注册全记录 5614 阅读
- 头条 宝塔面板安装指定历史版本的方法及第三方项目 6682 阅读
- 火爆 2022年申请Freenom免费域名的方法及相关问题集锦 9361 阅读
- 火爆 最新版Chevereto-Free1.6.x常见问题集锦 8068 阅读
- 头条 win10系统安装Python3以及环境变量的配置 4006 阅读
- 头条 定时任务中的Cron表达式详细说明 3517 阅读
- 头条 Backblaze B2注册及CloudFlare CDN设置 5886 阅读
- 神贴 利用OCI脚本创建甲骨文ARM免费VPS的方法 22812 阅读
- 神贴 2021最新注册Yandex免费域名邮箱的方法 12400 阅读
- 火爆 免费二级域名PP.UA申请激活保姆级教程 9766 阅读
- 火爆 准顶级域名EU.ORG申请使用的方法 10578 阅读
- 头条 使用instant.page,一段代码为你的网站加速 4479 阅读
- 头条 为你的网站引入APlayer和Meting,播放网易云、QQ等各平台音乐 3502 阅读
- 头条 VScode安装配置记录 4269 阅读
- 头条 Github自定义域名的那点事儿 3683 阅读
热门文章
## 前言 前面我们给大家介绍了怎....
话说注册Google Wave已经一段....
由于甲骨文云各区域登录时的服务器是不同的....

近期博客折腾日志
CSS,美化,更新,源码,代码,typecho,PHP

Emoji表情你了解多少?
Emoji
时隔五年终见Typecho正式...
正式版,升级,typecho
xiaohui Lv.1
4月3日
见到过!